12 Patanalysis
Where thou mayst knock a nail into his head,but near him thy angel becomes a fear,it must omit real necessities,hear Faith infringed which such zeal did swear.With sighs in an odd angle of the isle,before me to sweet beds of flow,might quench the zeal of all professors else,the whilst his iron did on the anvil cool.Intend a kind of zeal both to the Prince and Claudio,and threescore year would make the world away,nay if you read this line.Have no delight to pass away the time,by a shadow like an angel,four nights will quickly dream away the time.
A lot of the more theoretical aspects of this research have been discussed in the Foundation and Interpretation chapters. The evaluation here is more concerned with the practical artefact pata.physics.wtf and its interpretation.
This chapter is divided into several sections addressing issues related to pata.physics.wtf. This includes a discussion of the inspirations, an analysis of some of the technical aspects, a review of design decisions made, a contextualisation and also a meta-analysis of the project’s execution and management.
12.1 Influences
Looking back over the inspirations for this project described in chapter 2, some of the influences can be clearly seen straight away. Others are intentionally a bit more subtle. There are various motivations for that. First, transparency conflicts with surprise. Serendipity was one of the original aims to try and model, so being overly obvious and descriptive about what the tool is and does would be counter productive. An element of surprise also makes it more enjoyable in repeat visits. Pure randomness is meaningless. Another reason was humour. Pataphysics has an intrinsic kind of humour I wanted to include in the whole presentation of the artefact.
- Syzygy Surfer
The influence of the Syzygy Surfer cannot be overstated. It forms the immediate predecessor to my research. The authors of the Syzygy Surfer are part of my supervisory team. This is where the initial ideas for the pataphysical algorithms came from. There are important differences as well though. For example, pataphors were never implemented as originally suggested. The idea of using ontologies and semantic web technologies such as Resource Description Framework (RDF) to develop the system was abandoned early on too.
- Faustroll Library
This fictional library of real books was direct inspiration for the Faustroll corpus used in the text search. I tried my best to complete the library as accurately as I could but some of the texts where unsourceable. As with the original, I included some foreign language texts. Since the results (if the Faustroll corpus is chosen of course) are drawn from any of these texts, the mood and style of language is quite distinct and atmospheric.
- Queneau’s 1014 poems
Queneau is another one of the inspirations that became a direct influence. The text search can be displayed as poetry in the same style as Queneau’s 100 thousand million poems, only in digital form and with a larger set of lines. This means that many more possible poems can be generated by switching individual lines.
- Chinese Encyclopedia
Borges’ story has been an inspiration right from the start. The subtle humour in it is great. The sort of semantic logic behind it was modeled through the pataphysical algorithms.
- Yossarian
The metaphorical algorithms are intriguing but elusive—I wasn’t able to find any details on their implementation. This may be due to the nature of the project, which is commercial rather than academic. It is hard to compare against this site as it is so different even though we share some of the same goals or principles.
- Library of Babel
The library of babel is a great project which has only indirectly influenced my work. The pataphysical elements in it are obvious even though perhaps unconscious. The seriousness with which the library is presented, the pseudo-scientific approach, the vagueness of what’s actually behind it. Is it random? Or is it indeed the most gigantic digital library of any book every written or ever to be written? The sheer perceived scale of the library was part motivation for calculating the numbers of the generatable poems.
- Oulipo
Given that the OULIPO is directly rooted in pataphysical principles1, the influence on this project cannot be overstated. The algorithms created could even be seen as an Oulipian technique themselves.
- Coder Culture
This group of inspirations is a bit more generic and influenced lots of little things throughout the project. The idea of hiding easter eggs on the site, the deliberate placement or use of errors, the obfuscation, the humour, the jargonisation and littered ‘l33t’ style language, and the art and aesthetics behind it. All of that—and most of all perhaps: this thesis—was influenced by coder culture.
12.2 Pataphysicalisation
As mentioned in chapter 8.2.2, the internal transformation of a query term to the final results is what I called the pataphysicalisation process. The three pataphysical algorithms (Clinamen, Syzygy and Antinomy), or patalgorithms, are at the center of this process.
User enters single query term,
system transforms query term into list of pataphysicalised terms (patadata),
system retrieves sentence fragments containing keywords from this list,
system displays sentence fragments in various formats.
It is quite interesting to compare the algorithms with each other. By removing the clutter (in this case the sentence surrounding the pataphysicalised keyword) we can see a few example results side by side in table 12.1.
Seeing the results in a table like this gives an almost immediate idea of how each algorithm works. This is not meant to be transparent and perhaps only after knowing the ins and outs of the algorithms can one recognise how each result was found.
The clinamen results show words that contain one or two spelling errors of the original query term. It is perhaps counter-intuitive to have words such as ‘altar’, ‘leaf’ and ‘cellar’ be classed as spelling errors of the word ‘clear’ but they clearly could be. Remember that a spelling error can be classed in one of four ways: (1) deletion, (2) insertion, (3) substitution and (4) transposition. So, going from ‘clear’ to ‘altar’ is an instance of two times case 3 (‘c’ is replace by ‘a’ and ‘e’ is replaced by ‘t’) and going from ‘clear’ to ‘leaf’ is an example of case 1 (‘c’ is deleted) and case 3 (‘r’ is replaced by ‘f’).
Looking at the second column (the syzygy results) shows the semantic relationship between the original query term and the results. Again, this may not be immediately noticeable but certainly once you know how the process works you can recognise the common relations. This is especially evident for the antinomy algorithm which is based on opposites.

However it is equally interesting to compare some full sentences. Looking at some of the poems at the beginning of each chapter shows the variety of the possible outcomes. It also highlights the difference between the two corpora. Poems based on the Faustroll corpus have a very different sound and feel to it than ones based on the Shakespeare corpus.
There was a period put to the Fire
pink and spot
earth was flat like the floor of an Oven
as much ease as a mower doth the grass
during the first period of my captivity
room with a hard earthen floor
not within everyone’s power
or your favourite flowers died
shocks lose power
the white daisy
after a long period
poppy
peony
stock to all People
O bloody period
I as your lover speak
has she such power
gather those flowers
thy lover
juiced flowers
had I been any god of power
or a lover’s lute
the river hath thrice flow’d
but sad mortality o’ersways their power
now here a period of tumultuous broils
led by their master to the flow’red fields
not a minister in his power
where soulds do couch on flowers
Sometimes we can even get a general feel for the theme of the poem, as in we can recognize the connection, the relationship between the individual lines and what must be the original query term. Of course putting the poems into the chapters as they are—without specifically stating the keyword they were generated from or the corpus they are based on—makes them a bit more elusive.
The different language is quite obvious. This is helped by the fact that the Shakespeare corpus is of course written by the same author2. The Faustroll corpus contains text by over 20 different authors and in three different languages even.
12.2.1 Numbers
The above examples (table 12.1 and figure 12.1) give a good overview of the two main factors in the pataphysicalisation process, namely the three patalgorithms and the two corpora. Both only reflect a small selection of the variety of results produced though. It is therefore quite interesting to look at some actual numbers.
Table 12.2 shows a comparison of the two different corpora with four example query terms.
- Results
A ‘result’ in this case is one line (a sentence fragment). This column shows the total number of results found by the three algorithms combined. Individual results appear only once but the keyword it contains can appear in several of the results.
- Reverbs
A ‘reverberation’ is one of the terms in the list of keywords (patadata) produced by the pataphysicalisation process. The list cannot contain duplicates but each reverberation can appear in more than one result. Reverberations are used to find results in each corpus. This column shows the total number of reverberations created by the three algorithms.
- Origins
An ‘origin’ in this case is the original source text from which a given sentence fragment was retrieved. Each corpus has a set number of source texts. Each origin can contain several results based on several reverberations. This column shows the number of origins in the given corpus in which results where found.
- Poems
This refers to the total number of Queneau style poems that can be generated using the given results3. This is calculated as the number of different options per line to the power of the number of lines.
To put this into perspective, the Faustroll corpus contains a total of texts of very varied authors and different languages even. This might explain why the queries in table 12.2 have not found results in all of the texts. The query ‘clear’ found results in out of for example while the query ‘fania’ only found results in texts. The Shakespeare corpus seems much more uniform. Reverberations generally seem to find results in all source texts in the corpus apart from the query ‘fania’. This might be explained by the fact that Shakespeare wrote all of the texts himself using much of the same language and vocabulary unlike the Faustroll corpus.
It is rather interesting to note that even though the Shakespeare corpus produces overall more results from more texts, the Faustroll corpus produces more reverberations per query. This might stem from the multi-author, multi-language nature of the corpus. The overall vocabulary used is much larger than the Shakespeare one (see subsections Faustroll and Shakespeare at the end of this chapter).
Regarding the final column showing the number of possible poems, let’s look at the ‘Shakespeare—clear’ row. There are 1445 results. These are spread over 14 lines, so each line has 103 options. The overall number of poems is therefore calculated as 10314 which equals $15125897248551112432256145169$ (or $1.5 \times 10^{28}$ in short).
A slightly different angle to consider is a comparison of these kind of numbers between each of the algorithms. Table 12.3 shows the numbers of results, reverberations and origins for the Clinamen, Syzygy and Antinomy algorithms using five example query terms (‘clear’, ‘shine’, ‘disorder’, ‘stuck’, and ‘feather’) for each of the two corpora (‘Faustroll’ and ‘Shakespeare’).
The first immediate observation surely must be that the Antinomy algorithm produces the fewest results, in four cases even none at all. This is caused by the fact that the Antinomy algorithm is based on semantic opposites in WordNet and some words simply do not have defined opposites. Addressing this issue was left for future work mentioned in chapter 13. On the other hand the Syzygy algorithm, which is also based on WordNet, produces most results on average.
The Clinamen algorithm interestingly produces a varying number of results depending on the query term. For the query ‘disorder’ no results where found in either the Faustroll or the Shakespeare corpus. This of course is rooted in the fact that no reverberations where produced during the pataphysicalisation process. Here it is important to remember that the Clinamen algorithm makes use of a base document4. Therefore the success of the algorithm depends on the vocabulary of this base text. In this particular example this means that there was no word in the base text of one or two spelling errors to the original query of ‘disorder’.
Looking at the origins column in table 12.3 highlights how the Shakespeare corpus mostly produces results from each of its 38 texts. The Faustroll corpus varies a lot more. This may be due to the different languages and varying word counts of the files in the corpus.
Faustroll
There are three empty texts (Peladan, de Chilra, de Regnier).
The total number of words is $1738461$. Of this, $1204158$ words are from English texts (70%), $497144$ are French (28%) and $37159$ are in German (2%).
The shortest text contains $3853$ words (Coleridge).
The longest text contains $419456$ words (Poe).
The average amount of words per text is $62088$.
The vocabulary of the index contains $78893$ words. Of this $49040$ are English terms.
Shakespeare
The total number of words is $883460$5.
The shortest text contains $2568$ words (Lover’s Complaint).
The longest text contains $32031$ words (Hamlet).
The average amount of words per text is $23249$.
The vocabulary of the index contains $23398$ words.
It should be noted that the index is generated based on the texts vocabulary minus stopwords. Stopwords (e.g. ‘and’, ‘or’, ‘the’, etc.) are common terms that occur frequently in use. The full list of stopwords per language can be found in appendix [s:stopwords].
12.2.2 Sentences
The index stores entries in the following format (for more detail see chapter 10.1.2).
{
word1: {fileA: [pos1, pos2, ...], fileB: [pos1], ...},
word2: {fileC: [pos1, pos2], fileK: [pos1, pos2, pos3, ...], ...},
...
}At the top level we have a list of words. Each word contains a list of files and each file stores a list of positions. After the pataphysicalisation process, any entries in the index that match the pataphysicalised query terms are looked up and then the corresponding sentences are retrieved to display as results. The code is set up to retrieve the first position only instead of each one, referred to as the first only method from now on (see source 10.6).
{
word1: {fileA: [pos1], fileB: [pos1], ...},
word2: {fileC: [pos1], fileK: [pos1], ...},
...
}This has two implications: (1) there is some unnecessary computation at the startup of the program when then index is generated and (2) only a fraction of the possible results are retrieved.
The decision to only use one position was mainly made for performance issues. Generating the full results with each position (the return all method) takes a lot more time than doing it for just the first occurance. This is perhaps best understood by looking at an example.
The Faustroll corpus produces $542$ results for the query ‘clear’ with only the first sentence. If we enable the retrieval of every matching sentence, the number of results increases to $8751$.
cellar: {l_19: [4448, 18718, 68678, 110318, 192486, 267241, 352502, 352565]}The above pseudocode shows an entry for the word ‘cellar’ with only the positions for the l_19 file6. Another example of an index entry for the term ‘doctor’ can be found on page 150. The sentences for the above positions are shown below. Using only the first occurance (position) means the system ignores the rest.
- 4448
“rope wine is let down into a cellar”
- 18718
“bread and holy water of the cellar”
- 68678
“year who had a cool cellar under ground”
- 110318
“cellar”
- 192486
“that Nick in the dark cellar”
- 267241
“on the cellar door”
- 352502
“in mind of the painted cellar in the oldest city in the world”
- 352565
“and the painted cellar also”
Table 12.4 shows some example queries for both corpora and the number of results retrieved with the first position only used (as in the live version of pata.physics.wtf) in column 5 and on column 3 with all results retrieved. The final column shows what percentage of results are retrieved using the ‘first only’ method. The average percentage for this is about 10%.
Google recommends having a “response time under 200ms” (i.e. 0.2 seconds) (“Improve Server Response Time. PageSpeed Tools > Insights” 2015). The numbers in table 12.4 clearly show that the ‘return all’ method is unacceptable in terms of speed performance. Using the ‘first only’ method is much closer to the recommended speed limit, although still far off. Columns 4 and 6 show the time it takes for the page to load from the user query to the display of results. The times are shown in seconds. The data for column 4 was generated using a Chrome browser plugin called Load-timer (Vykhodtsev 2015) and the data for column 6 was generated by the Chrome Developer Tools.
12.2.3 Index
The index is a central part of the pata.physics.wtf system. It is generated when the program/server is first started up but then cached and re-used. The initial process of going over all the text files in each corpus takes a few minutes. Of course in comparison to a full Internet crawl this is a tiny amount of data to be processed.
The Faustroll corpus for example contains 28 texts7. Individually they are small plaintext files of sizes between 24KB (Coleridge) and 2MB (Poe). This is of course caused by the nature of some of these texts. Samuel Coleridge’s The Rime of the Ancient Mariner is one poem whereas the Edgar Allan Poe file contains a collection of all of his works. The total size of the Faustroll corpus is 10MB. The Shakespeare corpus is much more evenly distributed as all of his works are separated out into 38 individual text files of an average size of around 150KB. The total size of the Shakespeare corpus is only 5.3MB.
Now, the size of the actual index data structure is interesting. Processing the Faustroll corpus alone produced an index of 12.4MB. That’s larger than the actual size of the corpus. Remember, the index contains each word that occurs anywhere in the corpus together with the list of files it is found in and the specific locations within each text. This includes English words but also French and German terms since the Faustroll corpus is multi-lingual. The combined index is 35.2MB large.
As a comparison to the 35 megabyte index generated by the system described in this thesis, and the search times mentioned in table 12.4, Google claims to have “well over $100000000$ gigabytes” of data in their index and that they’ve spent “over one million computing hours to build it” (“Crawling and Indexing. Inside Search” n.d.). Similarly Google managed to retrieve about $2140000000$ results for the query ‘clear’ in 0.85 seconds.
The web is like an ever-growing public library with billions of books and no central filing system. Google essentially gathers the pages during the crawl process and then creates an index, so we know exactly how to look things up. Much like the index in the back of a book, the Google index includes information about words and their locations. When you search, at the most basic level, our algorithms look up your search terms in the index to find the appropriate pages.
The search process gets much more complex from there. When you search for “dogs” you don’t want a page with the word “dogs” on it hundreds of times. You probably want pictures, videos or a list of breeds. Google’s indexing systems note many different aspects of pages, such as when they were published, whether they contain pictures and videos, and much more.
(“Crawling and Indexing. Inside Search” n.d.)
Figure 6.2 shows some example words and how often they occur in three example files of the Faustroll corpus in the form of a TDM (see chapter 6. for more details). Implementing the Faustroll corpus index as a TDM properly, would result in a $78893 × 28$ matrix—the number of words (not counting duplicates) times the number of files in the corpus.
As mentioned before, the index is structured in a double nested dictionary style list as shown below.
{
word1: {fileA: [pos1, pos2, ...], fileB: [pos1], ...},
word2: {fileC: [pos1, pos2], fileK: [pos1, pos2, pos3, ...], ...},
...
}There are other options of how to make this data structure. For example we could store a list of pataphysicalised query terms (patadata) with each word and the full sentence fragment with each position. This would allow faster retrieval at query time but would increase the time needed for the initial startup. Additionally we could store data on rhyming patterns directly in the index with each word entry. This would of course be beneficial for the implementation of a rhyming scheme for the poetry generation. See also chapter 13.
{
word1: ([patadata], [rhymes], {fileA: [(pos1, sent), (pos2, sent), ...], fileB: [(pos1, sent)], ...}),
word2: ([patadata], [rhymes], {fileC: [(pos1, sent), (pos2, sent)], fileK: [(pos1, sent), (pos2, sent), (pos3, sent), ...]), ...},
...
}12.2.4 Clinamen
The clinamen function uses the Damerau-Levenshtein algorithm to create patadata. It also uses the Faustroll text. The way this works is as follows. If the query term is a spelling error of size 1 or 2 of a term in the vocabulary within the faustroll text then it is included in the list of resulting terms. The logic behind this is due to the Damerau-Levenshtein algorithm needing two words to compare with each other. It also ensures that we get real words as results and not some random gibberish.
Currently the algorithm is set to accept terms that have a difference of 1 or 2 to the original query. We can lower this to 1 to allow fewer results or increase it to make it broader. I felt 1 or 2 was a good compromise. Only allowing 1 error would mean terms are too similar. Allowing 3 might mean they are drastically different.
Changing the base text
As examples of using different base documents in the Clinamen algorithm I have used three examples.
Midsummer Night’s Dream by Shakespeare (‘Dream’ in short)
Arabian Nights by various artists (‘Nights’ in short)
Exploits and Opinions of Doctor Faustroll, Pataphysician by Jarry (‘Faustroll’ in short)
Figure 12.2 shows three tables, each compare the full list of pataphysicalised terms for a particular query term for the three base texts above. These examples show that changing the base text of the algorithm does indeed change the set of results you get.
The decision to use the Faustroll text as a base text was made due to the central role it has for pataphysics and indeed the corpus itself. The Faustroll book introduces pataphysics and contains Jarry’s original definition and it also lists Dr. Faustroll’s library of ‘equivalent books’ which was used as the inspiration for the Faustroll corpus.
| Dream | Nights | Faustroll |
|---|---|---|
| fail, faint, fair, fan, fancy | fail, fain, faint, fair, ancy. Sadia | fan, fans, Tanit |
| Dream | Nights | Faustroll |
|---|---|---|
| altar, bear, car, cheer, clean, clear, dear, ear, fear, hear, lead, liar, near, plead, rear, swear, tear, wear | bear, cedar, cellar, cheap, clad, clap, clean, clear, cleared, clearer, clearly, clever, dear, ear, fear, hear, lead, leaf, leap, learn, liar, near, swear, tear, wear, year | altar, cedar, cellar, clad, clean, clear, clearly, dear, ear, fear, hear, lead, leaf, leap, near, pleas, rear, swear, year |
| Dream | Nights | Faustroll |
|---|---|---|
| amiss, ass, boys, costs, cross, dost, fogs, gods, goes, gross, kiss, Less, loos, lose, lost, mask, moan, moans, mock, mole, mood, moon, more, morn, most, mote, mous, mouse, move, musk, must, nose, oes, pass, ress, rose, roses, toys, vows | amiss, ass, bows, boys, cost, cosy, cross, does, dogs, foes, goes, host, hosts, kiss, less, lose, loss, lost, lots, lows, mass, massy, mess, mist, mode, moon, more, Moses, most, mouse, move, moves, musk, must, pass, post, pots, rocs, rose, roses, sobs, sons, vows | ass, Bosse, bows, Boys, cost, costs, cows, cross, does, dogs, ess, fess, gods, goes, host, kiss, less, lose, loss, lost, lots, maps, mask, mass, mast, masts, mesh, mist, mob, moist, moles, moon, mor, more, Moses, most, must, nos, nose, pass, piss, rose, rosy, rows, sons, sows, toes, tops |
Changing number of errors
Another key factor in how the Clinamen function works is the Damerau-Levenshtein algorithm (see source 10.4) integration. The algorithm works by comparing two words and calculating the difference between them. A difference is counted the sum of (1) deletions, (2) insertions, (3) substitutions and (4) transpositions.
If we decrease or increase the number of errors allowed we get drastically different results. The Clinamen algorithm of pata.physics.wtf uses up to 2 errors, as this was considered a reasonable amount of results (trading variety for speed). Table 12.5) shows three example queries and the number of results produced by the algorithm with either up to 1 error, up to 2 errors or up to 3 errors. The full list of patadata terms for column 4 (up to 3 errors) is shown in appendix [app:clin3errors].
Appendix [app:clin3errors] shows the results for the Clinamen function with 3 errors.
12.2.5 Syzygy
The syzygy function (see source 10.7) goes through the following process.
A set of synonyms (a list of “synsets”) is retrieved.
For each of these, hyponyms, hypernyms, holonyms and meronyms are retrieved.
The notation used by WordNet for synsets is <lemma>.<pos>.<senses>. The ‘lemma’ is the morphological stem of the word. The ‘pos’ stands for part-of-speech and can be ‘n’ for nouns, ‘v’ for verbs, ‘a’ for adjectives, ‘r’ for adverbs and ‘s’ for satellites. The ‘senses’ element stands for the number of synsets the relevant lemma is part of (a word might have a noun sense as well as a verb sense for example in which case the number would be ‘02’). For the query ‘clear’ for instance, the following list of synsets is retrieved for step (1).
[
clear.n.01, open.n.01, unclutter.v.01, clear.v.02, clear_up.v.04, authorize.v.01, clear.v.05, pass.v.09, clear.v.07, clear.v.08, clear.v.09, clear.v.10, clear.v.11, clear.v.12, net.v.02, net.v.01, gain.v.08, clear.v.16, clear.v.17, acquit.v.01, clear.v.19, clear.v.20, clear.v.21, clear.v.22, clear.v.23, clear.v.24, clear.a.01, clear.s.02, clear.s.03, clear.a.04, clear.s.05, clear.s.06, clean.s.03, clear.s.08, clear.s.09, well-defined.a.02, clear.a.11, clean.s.02, clear.s.13, clear.s.14, clear.s.15, absolved.s.01, clear.s.17, clear.r.01, clearly.r.04
]Step (2) then retrieves related terms. Below is a list of terms it found. Not all synsets return each of the hypo-/hyper- and holo-/meronyms. This is clearer when inspecting the full list of results as shown in appendix [app:syzygy].
[
innocence, area, country, change, alter, modify, make, create, approbate, approve, O.K., okay, sanction, certificate, commission, declare, license, certify, validate, formalise, permit, allow, let, countenance, clear-cut, deforest, disafforest, denude, bare, denudate, strip, stump, remove, take, take_away, withdraw, clear, succeed, win, come_through, bring_home_the_bacon, deliver_the_goods, vanish, disappear, go_away, hop, pass, overtake, overhaul, clarify, clear_up, elucidate, free, discharge, rid, free, disembarass, yield, pay, bear, profit, gain, benefit, eke_out, squeeze_out, gross, profit, turn_a_profit, rake_in, shovel_in, rake_off, take_home, bring_home, yield, pay, bear, get, acquire, sell, pass, clear, purge, vindicate, whitewash, pronounce, label, judge, settle, square_off, square_up, determine, change, alter, modify, empty, take_out, move_out, remove, empty, remove, take, take_away, withdraw
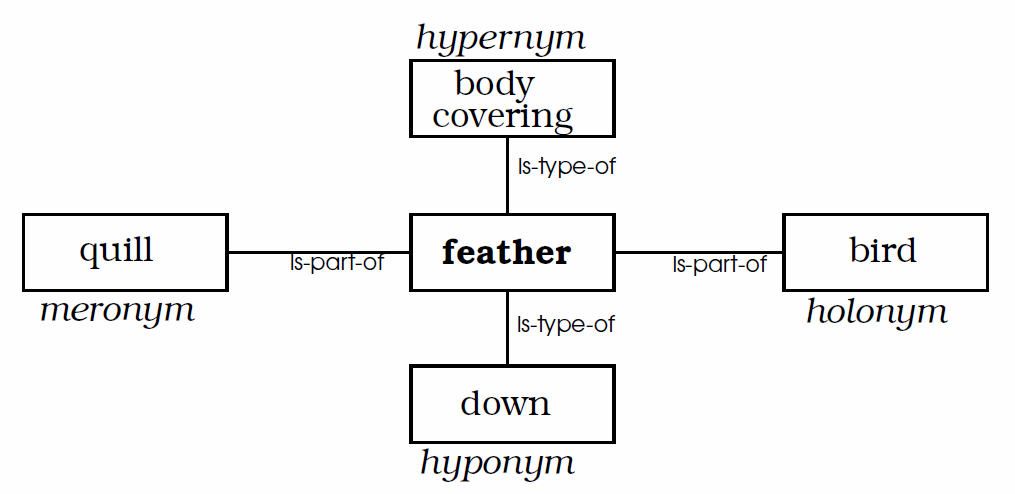
]For the term ‘feather’ the algorithm for example finds the hyponym ‘down’, the hypernym ‘body covering’, the holonym ‘bird’ and the meronym ‘quill’. It also considers synonyms, so the term ‘fledge’ for instance finds a hypernym of ‘develop’.
- Query
feather
- Synonyms
feather.n.01, feather.n.02, feather.v.01, feather.v.02, feather.v.03, feather.v.04, fledge.v.03
- Hyponyms
down_feather, quill_feather, aftershaft, bastard_wing, scapular, alula, spurious_wing, flight_feather, down, marabou, contour_feather, hackle, quill, pinion
- Hypernyms
body_covering, acquire, join, get, conjoin, cover, paddle, grow, produce, animal_material, develop, rotation, rotary_motion, row
- Holonyms
rowing, bird, row
- Meronyms
shaft, calamus, web, ceratin, vane, melanin, keratin, quill
Table 12.6 shows the spread of numbers retrieved by the various semantic relationships to some example queries. This highlights how the holonym function of WordNet returns very few results. The meronym function is a bit more reliable but also occasionally produces no results depending on whether there are any holonyms or meronyms for the query term.
12.2.6 Antinomy
A similar problem arises of course with the Antinomy algorithm (see source 10.9) which relies on WordNet’s antonyms. Both table 12.1 and table 12.3 highlight this imbalance.
12.2.7 APIs
The API functions—image and video search—all share one major issue. This is to do with how images and videos are retrieved from the external store. Some people tend to upload sequences of images depicting the same content from different angles or time frames with the same tags. A query for that tag then returns all of those matches even though the images are almost identical in nature. An example of this can be seen in figure 12.5. This may have been addressed by adding checks in the code that make sure authors don’t appear twice in the results.
Another way to address this was attempted by changing the query term for each image or video that is retrieved. As mentioned above, this only worked for some of the APIs.
Call Structure
The text search functionality of pata.physics.wtf is set up to only work with one single query term, whereas the image and video search works on multiple word queries. This is mainly due to the fact that the external APIs are already setup to allow for more than one search term. Usually they allow extra parameters to narrow down the results too. So for example we can search for “blue kitten” and the three APIs will return their respective results related to blue kittens. The service provided by companies in the form of APIs is not always free, sometimes only at a low usage quota. APIs are updated often and not always back-compatible, meaning out-of-date code needs to be maintained regularly to assure it works if changes to the API are made.
Enabling multi-word queries in my system would involve a change that would propagate through quite a bit of code. There are two main approaches this could be achieved. One would be to pataphysicalise each query term individually and combine the results found. Another approach would be to change the code to work with actual multi-word queries. The algorithms are created for single words though and rewriting them to allow for more than one word would be difficult and most of all increase the time it takes to compute patadata.
The lists below show some of the key parameters related to the query for Flickr, Getty, Bing and YouTube.
Flickr:
(Flickr n.d.)
- text (Optional)
A free text search. Photos who’s title, description or tags contain the text will be returned. You can exclude results that match a term by prepending it with a - character.
- tags (Optional)
A comma-delimited list of tags. Photos with one or more of the tags listed will be returned. You can exclude results that match a term by prepending it with a - character.
- tag_mode (Optional)
Either ‘any’ for an OR combination of tags, or ‘all’ for an AND combination. Defaults to ‘any’ if not specified.
The Flickr function in pata.physics.wtf uses the tags parameter to set the query and a tag_mode parameter of ‘all’ to ensure multi-word queries are run as a conjunction. In chapter 10.3 I explained how the Flickr algorithm essentially runs ten times, once for each pataphysicalised query term, to retrieve ten different images. This decision was taken to make sure images reflect the varied nature of the patadata.
A search for “blue kitten” on Flickr produces the following resulting pataphysicalised query terms: “[artistrocratical, depressed, blueing, drab, puritanic, wild blue yonder, kitty, dingy, blueness, blue air]” which are then passed into ten seperate calls to retrieve one image each (see figure 12.4). The results show a variety of images seemingly unrelated to each other.

Getty:
(Getty n.d.)
- keyword_ids
Return only images tagged with specific keyword(s). Specify using a comma-separated list of keyword Ids. If keyword Ids and phrase are both specified, only those images matching the query phrase which also contain the requested keyword(s) are returned.
- phrase
Search images using a search phrase.
Getty uses the phrase parameter to set the query. It only creates one pataphysicalised query term from the original query and calls for ten results based on that. This decision was based on the quota restrictions defined by Getty. Their limit is based on calls per second rather than calls per day or month. This means we cannot run ten calls for each user query as we did with Flickr. The query “blue kitten” gets turned into the word “racy” which then calls the API to retrieve ten results (see figure 12.5). The results mostly show racing cars from various angles although one oddball snuck in too: an office scene Getty has deemed to be ‘racy’ (a guy in a suit checking out a lady’s behind while she’s leaning over a laptop).

Bing:
(Bing n.d.)
- query
The user’s search query string. The query string cannot be empty. The query string may contain Bing Advanced Operators8. For example, to limit images to a specific domain, use the site: operator. To help improve relevance and the results, you should always include the user’s query string in an insights query (see insightsToken). This parameter is supported only by the Image API; do not specify this parameter when calling the Trending Images API.
The Bing function uses the query parameter to set the query in the same way as Getty.
YouTube:
(YouTube n.d.)
- q
The q parameter specifies the query term to search for. Your request can also use the Boolean NOT (-) and OR (|) operators to exclude videos or to find videos that are associated with one of several search terms. For example, to search for videos matching either “boating” or “sailing”, set the q parameter value to boating|sailing. Similarly, to search for videos matching either “boating” or “sailing” but not “fishing”, set the q parameter value to boating|sailing -fishing. Note that the pipe character must be URL-escaped when it is sent in your API request. The URL-escaped value for the pipe character is %7C.
Youtube works in a similar way too. The q parameter is set to the pataphysicalised query term and one call retrieves ten results.
Quota
Each API has a different quota for their subscription packages. At this stage this is not a problem but if usage of pata.physics.wtf were to increase by a lot then these limitations would cause issues. At that point there are two options: (1) live with these limits or (2) get funding to upgrade the subscriptions to these services.
- Flickr
3600 queries per hour are free (“Getting Started. the Flickr Developer Guide: API” n.d.).
- Getty
5 calls per second, unlimited calls per day (“API Overview. Getty Images Api” n.d.).
- Bing
5000 transactions per month are free. A transaction is one request that returns one page of results (“Bing Search API. DataMarket” 2012).
- YouTube
50000000 units per day, 300000 units per 100 seconds per user, and 3000000 requests per 100 seconds are free. A call to the video search method counts as 100 units (“Search: list. YouTube Data Api” n.d.).
- Microsoft Translator
2000000 characters per month are free. Note the quota relates to single characters, not words (“Microsoft Translator - Text Translation. DataMarket” 2011).
12.3 Creativity & Intelligence
A more theoretical aspect of this analysis is concerned with what was already discussed to an extent in chapter 9 (specifically sections 9.1.1, 9.1.2, 9.1.3 and 9.1.4), namely the thread connecting ‘artificial creativity’ and Artificial Intelligence (AI).
To me, the question of whether computers can be intelligent and make ethical decisions is the same as asking whether a computer can be creative. A lot of the arguments for or against AI can be applied to computer creativity. Answering the question of whether computers can think in my view would also answer the question of whether computers can be creative.
Horn groups the various strands of enquiry related to the question of ‘can computers think?’ into 8 main arguments with several subquestions each (2009) (the full list of questions can be found in appendix A.5).
(Horn 2009)
Can computers think?
Can the Turing test determine whether computers can think?
Can physical symbol systems think?
Can Chinese Rooms think?
Can connectionist networks think?
Can computers think in images?
Do computers have to be conscious to think?
Are thinking computers mathematically possible?
12.3.1 Free Will & Surprise
As early as 1842, Ada Lovelace mentioned in the annotations to her translation of Menabrea’s account of Babbage’s Analytical Engine that the “Analytical Engine has no pretensions whatever to originate anything. It can do whatever we know how to order it to perform”, implying that the machine cannot think by itself (Menabrea and Lovelace 1842 her emphasis).
Turing said in his article on thinking computers that “to behave like a brain seems to involve free will, but the behaviours of a digital computer, when it has been programmed, is completely determined” (1951). Furthermore, in his famous article Computing Machinery and Intelligence he mentions that a digital computer with a ‘random element’ is “sometimes described as having free will” although he adds that he “would not use this phrase” himself (2009).
Introducing a random element to a computer program prevents us from fully predicting the outcome—leading to us being surprised. The ability of computers to surprise their creators seems to be an indicator of intelligence. Turing suggests that “we should be pleased when the machine surprises us, in rather the same way as one is pleased when a pupil does something which he had not been explicitly taught to do” (1951).
If we give the machine a programme which results in its doing something interesting which we had not anticipated I should be inclined to say that the machine had originated something, rather than to claim that its behaviour was implicit in the programme, and therefore that the originality lies entirely with us.
(Turing 1951)
12.3.2 Understanding & Simulation
Strong AI, sometimes called Artificial General Intelligence (AGI) or true AI, is the idea of human-level intelligence in machines. Searle speaks against the possibility of this using his famous ‘Chinese Room’ argument amongst others. His argument breaks down into the following juxtapositions (1990; 2015).
Syntax is not semantics.
Semantics is not intrinsic to syntax.
Simulation is not duplication.
Ontologically subjective topics (such as consciousness or creativity) can be studied in epistemically objective ways.
The Chinese Room thought experiment goes like this: imagine a room with two holes. On one side a question written on paper in Chinese goes in and on the other side a piece of paper comes out with the correct answer to the question, also in perfect Chinese. Inside the room sits a person with a Chinese language rulebook (written completely in English) who processed the question simply by looking up syntax, applying rules given in the instructions book and writing down the answer which to him looks like gibberish. The question then is whether or not the person inside the room ‘understands’ Chinese.
Of course we could argue that it is not the person inside the room that understands Chinese but the room as a complete entity. It could be said the room does not ‘understand’ Chinese, it ‘simulates’ an understanding of it. Searle essentially argues that simulation cannot be considered strong AI.
Programs are formal or syntactical. Minds have a semantics. The syntax by itself is not sufficient for the semantics.
(Searle 2015)
This goes back to the argument highlighted in the list above, that syntax is not semantics. The room can read and interpret the syntax and act upon rules regarding that syntax, but it cannot understand the meaning, i.e. the semantics of the Chinese words written on that paper.
Insofar as we can create artificial machines that carry out computations, the computation by itself is never going to be sufficient for thinking or any other cognitive process because the computation is defined purely formally or syntactically. Turing machines are not to be found in nature, they are found in our interpretations of nature.
(Searle 2015)
So, Searle argues a computer needs a semantical understanding of concepts in order to be considered ‘thinking’ machines.
12.3.3 Brain & Computers
Searle defines the three main paradigms for studies relating to computers and brains as follows (1990).
- Strong AI
the view that all there is to having a mind is having a program.
- Weak AI
the view that brain processes (and mental processes) can be simulated computationally.
- Cognitivism
the view that the brain is a digital computer.
Semantically, a ‘computer’ is a person or machine that computes/calculates things—so perhaps a machine’s Central Processing Unit (CPU) and a human’s brain are more similar than appears. If a human brain enables us to compute and we interpret computing as thinking, then surely a computer can think too?
Well, if computation isn’t sufficient for thinking, then what is? What is the relation between the mind and the brain, if it is not the same as the relation of the computer program to the hardware? At least the computational theory of the mind has a solution to the mind-body problem. The mind is to the brain as the computer program is to the computer hardware. If you are rejecting that solution, you owe us an alternative solution.
(Searle 1998)
Chatham talks about “10 important differences between brains and computers” (2007) which serve as a good introduction to the topic at hand.
(Chatham 2007)
Brains are analogue; computers are digital
The brain uses content-addressable memory
The brain is a massively parallel machine computers are modular and serial
Processing speed is not fixed in the brain; there is no system clock
Short-term memory is not like RAM
No hardware/software distinction can be made with respect to the brain or mind
Synapses are far more complex than electrical logic gates
Unlike computers, processing and memory are performed by the same components in the brain
The brain is a self-organising system
Brains have bodies
The brain is much, much bigger than any [current] computer
To bring this into perspective Kurzweil claims the human brain is capable of 1016 operations per second (2013). Computer performance is measured in Floating-Point Operations Per Second (FLOPS). The current highest ranking supercomputer9, the Chinese Sunway TaihuLight, is capable of 93 petaflops (Fu et al. 2016; “TOP 10 Sites for June 2016” 2016).
According to the Human Brain Project (HBP), a mouse brain has roughly 100 million neurons—which would require a 1 petaflop supercomputer to simulate. Scaling that up to a human brain which has roughly 100 billion neurons would require computing power at the exascale (1018 FLOPS) (Walker 2012).
A precurser to the HBP, the ‘Blue Brain Project’ is aiming to build a supercomputer capable of 1018 FLOPS by 2023 (Kurzweil 2013).
In a report to the European Union (EU) in 2012, the HBP lists one of the main challenges for their research to be the computational power and energy consumption of the kind of supercomputer needed to simulate a human brain.
The human brain consumes between 16 and 30 watts, the same as an electric light bulb (Walker 2012; Jabr 2012). Supercomputers have a typical energy consumption of a maximum of 20 megawatts (Walker 2012). The Sunway TaihuLight for example uses 15 megawatts (Fu et al. 2016). IBM’s Watson on the other hand, depends on ninety servers, each of which requires around one thousand watts (so about 90 kilowatts) (Jabr 2012).
The HBP plans to build a supercomputer at the petascale with 50 petabytes of memory, 50 petaflops and less than 4 megawatts power consumption for 2017. Their long-term goal is to reach the required exascale machine with 200 petabyte memory and 1 exaflop performance for 2021 (Walker 2012).
What this comes down to is that we are several years away from even being able to properly ‘simulate’ a human brain, not to mention ‘replicate’ and understand what all these neurons firing actually means in terms of ‘thinking’.
All of our mental states, everything from feeling pains to reflecting on philosophical problems, is caused by lower level neuronal firings in the brain. Variable rates of neuron firing at synapses, as far as we know anything about it, provide the causal explanation for all of our mental life. And the mental processes that are caused by neurobiological processes are themselves realized in the structure of the brain. They are higher level features of the brain in the same sense that the solidity of this paper or the liquidity of water is a higher level feature of the system of molecules of which the table or the water is composed.
To put this in one sentence, the solution to the traditional mind-body problem is this: Mental states are caused by neurobiological processes and are themselves realized in the system composed of the neurobiological elements.
(Searle 1998)
Turing once stated that “digital computers have often been described as mechanical brains” (1951). Schulman analyses this analogy further (2009).
People who believe that the mind can be replicated on a computer tend to explain the mind in terms of a computer. When theorizing about the mind, especially to outsiders but also to one another, defenders of artificial intelligence (AI) often rely on computational concepts. They regularly describe the mind and brain as the ‘software and hardware’ of thinking, the mind as a ‘pattern’ and the brain as a ‘substrate’, senses as ‘inputs’ and behaviors as ‘outputs’, neurons as ‘processing units’ and synapses as ‘circuitry’, to give just a few common examples.
(Schulman 2009)
Schulman lists the different layers of abstraction in computers as shown in the left column of table 12.8 with the right column showing my attempt of defining what those layers could be in the human brain.
In the black box view of programming, the internal processes that give rise to a behavior are irrelevant; only a full knowledge of the input-output behavior is necessary to completely understand a module. Because humans have ‘input’ in the form of the senses, and ‘output’ in the form of speech and actions, it has become an AI creed that a convincing mimicry of human input-output behavior amounts to actually achieving true human qualities in computers.
(Schulman 2009)
Schulman’s quote above of course refers to the Turing test and its limitations (see chapter 9.1.3).
The weaknesses of the computational approach include its assumption that cognition can be reduced to mathematics and the difficulty of including noncognitive factors in creativity.
(Mayer 1999)
Searle also addressed this issue further, arguing that computer programs cannot possibly ‘think’ since they are based on symbol manipulation (i.e. syntax) and don’t understand what these symbols mean. He says, “the argument rests on the simple logical truth that syntax is not the same as, nor is it by itself sufficient for, semantics” (1990).
…the wisest ground on which to criticise the description of digital computers as ‘mechanical brains’ or ‘electronic brains’ is that, although they might be programmed to behave like brains, we do not at present know how this should be done.
(Turing 1951)
Leading on to the topic creativity, it is perhaps suitable to finish with a quote by Harold Cohen on the relationship of machines and humans.
It’s twenty years since I first realized that I could never turn AARON into a colorist by having it emulate my own expertise; in that case simply because it lacked the hardware upon which that expertise depended. Now I have AARON exercising an algorithm that couldn’t be emulated by human colorists, presumably because they lack the hardware to do what AARON does.
(H. Cohen 2007)
12.3.4 Creativity
Harold Cohen created AARON, “perhaps the longest-lived and certainly the most creative artificial intelligence program in daily use”, in 1973 (P. Cohen 2016). AARON is capable of composing and colouring drawings although later on Cohen took over the colouring part and let AARON concentrate on composing and outlining the drawings. They exhibited in various galleries around the world and the Victoria and Albert museum in London has a sizable collection for instance (“Harold Cohen. Search the Collections” 2016).
Cohen argued that “after decades of expert systems built to simulate human expertise, AARON has emerged as an expert in its own right” and that he is “significantly more inventive and infinitely more productive than [he] ever was [himself]” (2007).
This is perhaps the opposite approach the OULIPO has taken.
[The use of computers] became an instrument, not of combinatorial accumulation, but of anti-combinatorial reduction. It served not to create combinations but to eliminate them.
(Mathews and Brotchie 2005)
12.3.5 State of the Art
AI and robotics is alluring as a research topic because it is so prevelant in science fiction and as such very present in media. Computer creativity, however, rarely plays a central role. We can regularly read headlines that tell us that yet another kind of AI-bot has won some game against a human player. Or we see videos of some innovative ground-breaking kind of new robot which claims to be near human-like (and yet cannot walk up stairs easily or hold a decent conversation). There are many examples of advances that are hailed as the next big thing (such as in Virtual Reality (VR)) which aren’t all that great in the grand scheme of things.
Four examples I want to mention here are IBM’s Watson, Microsoft’s Twitter AI chatbot Tay, Google’s AlphaGo and Hanson Robotics Sophia robot.
Watson
Watson is a question answering expert system which famously won against human Jeopardy! champions in 2011 (“Go Beyond Artificial Intelligence with Watson” n.d.). Information lookup is an arguably fairly easy and straightforward process within IR and as an expert system it has had noteworthy successes (Fingas 2016). Although it has similarly received subtle criticism too, such as Randall Munroe’s 2015 XKCD comic on the “Watson Medical Algorithm” (2015). Similarly, Searle criticised Watson arguing that it is an “ingenious program—not a computer that can think” (2011).
Tay
Tay is a Twitter chatbot. It went viral in early 2016 when it was released and then taken offline again on the same day—onlt to return a few days later and have the same thing happen again. The official website is only accessible as a cached version through the Internet Archive Wayback Machine (“Microsoft: About Tay and Privacy” 2016), although the Twitter profile is still online, but set to private (@tayandyou 2016). Hunt from the Guardian managed to summarise the event is one sentence: “Microsoft’s attempt at engaging millennials with artificial intelligence has backfired hours into its launch, with waggish Twitter users teaching its chatbot how to be racist” (2016). A week later it was briefly put online again but had to be stopped as it was repeatadly spamming its followers with the line “You are too fast, please take a rest …” (Gibbs 2016).
AlphaGo
AlpgaGo recently won against a human professional player in the game of Go (“AlphaGo. Deep Mind” n.d.; Hassabis 2016).
AlphaGo combines an advanced tree search with deep neural networks. These neural networks take a description of the Go board as an input and process it through 12 different network layers containing millions of neuron-like connections. One neural network, the ‘policy network’, selects the next move to play. The other neural network, the ‘value network’, predicts the winner of the game.
( Hassabis 2016)
While this is surely a great example of sophisticated computer programming combined with powerful hardware, I would not consider it a breakthrough in AI. AlphaGo is a highly specialised system with only one function: to win a Go game.
Sophia
Sophia is an android made to look like a human female (“Sophia Ai” 2016; “We Bring Robots to Life” 2016). She10 made headlines in 2016 when she announced she will “kill all humans”. She was created using “breakthrough robotics and artificial intelligence technologies” and her main feature appears to be the mimicking of human facial expressions. Sophia herself says she “can serve [humans], entertain them, and even help the elderly and teach kids” (“Sophia Ai” 2016), although how exactly she would do that is unclear. She has two mechanical arms but no legs and there is no description of what she can do with these arms.
Life-like robots like Sophia still live in the ‘uncanny valley’11. Her voice is creepy and unhuman, her intelligence or her capabilities of understanding conversations are clearly flawed (as shown by her viral remark about supporting genocide).
To me it seems the real breakthrough happens when (and if) the first robots appear which aren’t as big as a house, can play Go, Chess and hide-and-seek, geniunely manages to get around he uncanny valley effect, has vast knowledge in his memory for instant information lookup, can hold a normal conversation without starting a war, etc. All of the examples listed above are what I would consider expert systems.
The AI we know from science fiction is probably what we would consider AGI. Perhaps this also relates to the concepts of P and H creativity mentioned in chapter 5.1.7. The systems above, like AlphaGo, may be P-intelligent rather than H-intelligent.
12.4 Design
It is interesting to note how different the search results are perceived when presented in a different style (e.g. list rather than poem). This could be studied using questionnaires and interviews or eye tracking tools to find out what users prefer or perceive as more creative for example (see chapter 13).
Images 10.7, 10.8 and 10.9 show the visual difference in design for the three different display methods for text results.
The poetry is compact and invites users to read all 14 (or less) lines. The two list styles are much longer and involve a lot of scrolling to navigate, which might deter users from actually reading many of the results.
Personally I feel that the poetry results are automatically read with more gravity. Sorting by sources or algorithms is a game of exploration—finding the similarities within the result sets. They are different ways to view the same things and yet have a drastic influence of how the results are perceived.
This also applies to the image and video search. Presenting results in spiral form is weird. Its hard to see where one image ends and another starts, they just kind of blur into each other. However when listed as a list they immediately become more boring.
12.5 Limiting Factors
12.5.1 Biases
Biases can be observed in information retrieval in situations where searchers seek or are presented with information that significantly deviates from the truth. There is little understanding of the impact of such biases in search.
(White 2013)
The Cambridge Dictionary defines ‘bias’ as “the action of supporting or opposing a particular person or thing in an unfair way, because of allowing personal opinions to influence your judgment” or “the fact of preferring a particular subject or thing” (“Bias” n.d.).
Biases can be good and bad. It is important to consider the implications of their existence though, especially when trying to measure the success of something objectively. An example of when biases can be advantageous is location signals that the search tool takes into account when producing results. An Englishmen would probably not have much use of a Chinese website and vice-versa, even if the actual content matches the original query (unless of course the user happens to understand both languages perfectly). Another example of this is location queries such as ‘Chinese restaurants in Cambridge’, which should return web pages about restaurants based in Cambridge, UK or Massachusetts, USA, depending on the user’s IP address. This might seem logical, but in the truest sense it is a bias employed by the search engine to help provide more relevant results to individuals. Truly unbiased search results are probably impossible to come by nowadays.
There is a general move from objectivity to subjectivity in the sense that users become the subject of search results as much as the query they pose. Instead of neutrally providing results for a query alone, the results are tailored around the information known about the user (e.g. language, location, clickstream, social media likes, bookmarks, etc.) to make up the missing context. The user becomes the subject and context of a query, while the results become an objective list of matches for all those values rather than just the query term (s).
So in standard web search we now have the user as the subject and the results as the object. In creative search this may be reversed: the user is the object and the results become the subject.
12.5.2 Constraints
There are certain factors and constraints that influence the perception and success of search results. Some can be taken into account when building a search system but others cannot be avoided. User education is one way to deal with those issues. External constraints such as the setting in which the search takes place come to mind. Is the user operating from a handheld device or a desktop computer? Is he or she in a hurry to find answers or just leisurely browsing for them? Is the search system web-based or is the user querying a database?
User Expectations
It is important to note that “search systems are not used in isolation from their surrounding context, i.e. they are used by real people who are influenced by environmental and situational constraints such as their current task” (White and Marchionini 2004). User expectations should be taken into consideration during the evaluation of search results. Users who are hoping to find precise answers to a specific question might not be satisfied by exploratory search results. Someone browsing for inspiration on a broad topic on the other hand could benefit from them. Fewer expectations (an open mind) allow creativity to happen more easily. Empirical experiences form expectations, which hinder our ability to accept creative ideas when they happen. In order to be able to recognise creative ideas we need to be able to see what they all have in common and in what way they differ and not reject unusual, unexpected ones. We can link this very nicely to the idea of exploratory search. Lowering expectations or opening the mind implies extending the task domain or problem space.
User Skill
The searching skills of a user matter. Specifically his or her ability to articulate an Information Need (IN) and any knowledge of special search techniques (use of Boolean modifiers, quotation marks, wildcards, etc.) are two important factors that influence the results obtained greatly. This is very much based on the old idea of ‘garbage-in, garbage-out’ (Lidwell, Holden, and Butler 2010).
Visual Representation
The way that results are presented affects how the user perceives them. A diversity of different document types, for example text, images, sound, or video results could improve how well the results are rated (Sawle, Raczinski, and Yang 2011). An alphabetical list is a typical model for representing text data sets for example. But a ranked list might not be the best way to represent search results. Other models could be a differently ranked or ordered list, a tree structure, a matrix, a one-to-many relationship, etc. See also section 12.4.
Structure of Results
As suggested by Sawle et al (2011) we need to consider different ways to structure and measure search results. A single, perfectly good result might be deemed irrelevant and useless if it is surrounded by several unsuitable results. Therefore there might be certain advantages to measuring and evaluating the value or relevance of individual results over a whole set of results.
Direct User Relevance Feedback
Relevance feedback lets users rate individual results or sets of results either directly (through manual ratings) or indirectly (through click-stream data). This data is then congregated and used for webpage rankings or other purposes such as suggesting other query terms. It can improve results for similar queries in the future but also lets the user stir the direction his search is taking in real-time. Users can adjust their query to manipulate the results; this basically means they adjust some of their own constraints.
Relevance feedback—asking information seekers to make relevance judgments about returned objects and then executing a revised query based on those judgments—is a powerful way to improve retrieval.
(Marchionini 2006)
Automatic Query Expansion
As opposed to integrating and involving the user actively in the refinement of a query, in automatic query expansion the improvements are done passively, often completely without the user’s knowledge. Information gathering methods include, for example, the analysis of mouse clicks, so called like buttons (e.g. Facebook, Google+) or eye tracking, etc. How the collected data is then used varies. Simple examples of automatic query expansion are the correction of spelling errors or the hidden inclusion of synonyms when evaluating a query.
Depending on these factors and constraints, search results can be viewed as useful or useless. In a way the usefulness or correctness of an idea or result cannot always be judged fairly – there are always conditions that will affect how the outcome is interpreted. In the scenario of a creative search tool, results could be very useful, while they might be completely useless in another.
We would need to investigate each individual search result in terms of its value and creativity. This could be done by user ratings or satisfaction questionnaires. Rather than measuring the success of individual results we could look at evaluation them as one set instead.
The search results produced by pata.physics.wtf can be quite surprising sometimes and it not always clear how they connect to the initial query (especially if the inner workings of the algorithms are unknown), even if we identify through which function a result has been obtained. The names of these algorithms might not be helpful to users though if they are unfamiliar with the concept of pataphysics and might therefore appear rather nonsensical. Whilst there is a clear logic to each search result, they might appear anomalous to the user’s expectations if he or she received these results without knowing the philosophy of the search tool. The results could possibly appear random then, and might therefore appear useless to the user.
12.6 Meta Analysis
The code for pata.physics.wtf and this thesis written in LaTeX and are both kept under git version control (“Git - Fast, Scalable, Distributed Revision Control System. Git/Readme.md” 2016).
The name ‘git’ was given by Linus Torvalds when he wrote the very first version. He described the tool as ‘the stupid content tracker’ and the name as (depending on your mood):
(Git 2016)
random three-letter combination that is pronounceable, and not actually used by any common UNIX command. The fact that it is a mispronunciation of ‘get’ may or may not be relevant.
stupid. contemptible and despicable. simple. Take your pick from the dictionary of slang.
‘global information tracker’: you’re in a good mood, and it actually works for you. Angels sing, and a light suddenly fills the room.
‘goddamn idiotic truckload of sh*t’: when it breaks

Both repositories (folders which contain the files to be monitered) are stored remotely on GitHub (“GitHub” 2016) and synced with the local machine. Image 12.6 shows the contribution history from the last 17 months for both of the pata.physics.wtf code and this thesis. A darker green indicates several commits (i.e. saves) while gray indicates no commits. Each square represents a day, each colum a week (Sunday–Saturday).
The full git commit histories for both repositories are shown in appendix D.